Which Service Mesh Should I Use?


If you’re managing cloud native microservices, you’ve heard of a service mesh, and you understand why you would need one, then this article is for you. When you start looking more closely at using a service mesh, you may suddenly realize the many options available. What should you choose? How can you figure out the differences between them and what might be right for you? This article provides an objective vendor-neutral guide to help you get started.
A service mesh is a dedicated infrastructure layer for managing service-to-service communication to make it visible, manageable, and controlled. The exact details vary between products, but generally speaking, there are common things you can expect in a “service mesh.”
The Common Attributes of a Service Mesh
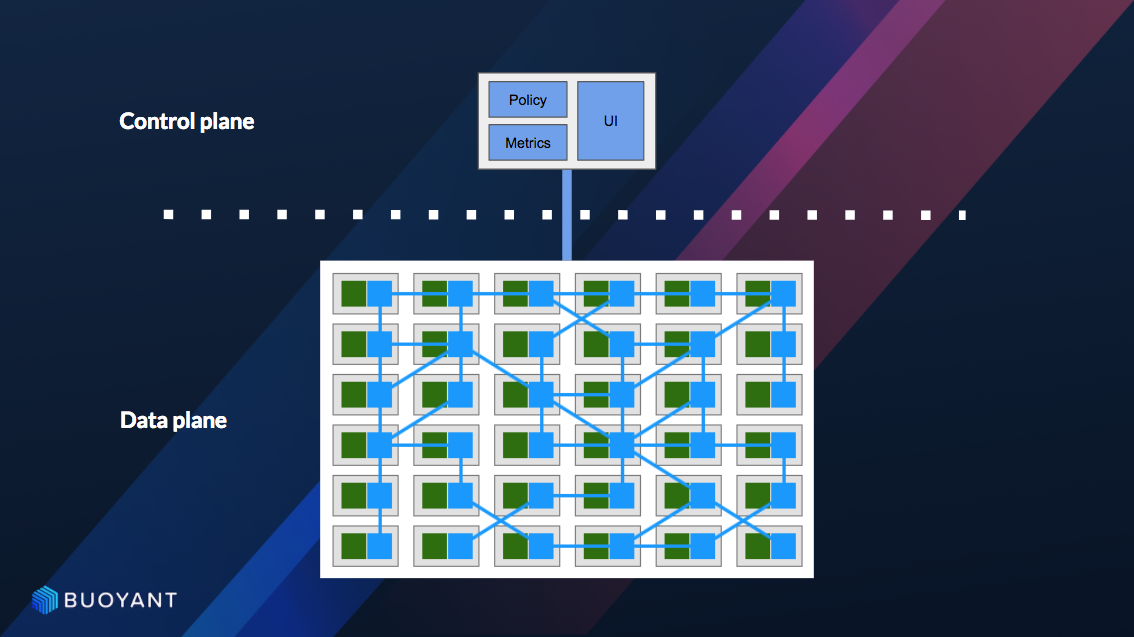
In the basic architectural diagram above, the green boxes in the data plane represent applications, the blue squares are service mesh proxies, and the rectangles are application endpoints (a pod, a physical host, etc). The control plane provides a centralized API for controlling proxy behavior in aggregate. While interactions with the control plane can be automated (e.g. by a CI/CD pipeline), it’s typically where you–as a human–would interact with the service mesh.
Any service mesh in this guide has certain features that should be considered table stakes:
- Resiliency features (retries, timeouts, deadlines, etc)
- Cascading failure prevention (circuit breaking)
- Robust load balancing algorithms
- Control over request routing (useful for things like CI/CD release patterns)
- The ability to introduce and manage TLS termination between communication endpoints
- Rich sets of metrics to provide instrumentation at the service-to-service layer
The specifics of those features–how they’re implemented, config options, etc–vary between products. But, at a high level, those should be considered standard things that any service mesh should provide. This guide will instead focus on differentiating features between products.
What’s Different About a Service Mesh?
The service mesh exists to make your distributed applications behave reliably in production. With microservices, service-to-service communication becomes the fundamental determining factor for how your applications behave at runtime. Application functions that used to occur locally as part of the same runtime instead occur as remote procedure calls being transported over an unreliable network. The success or failure of complex decision trees that reflect the needs of your business now require you to account for the reality of programming for distributed systems.
As a result, when we (vendors) advocate for the “service mesh,” we tend to focus on managing the messages (or API calls) in those remote procedures. Inevitably, comparisons are then made between the service mesh and other message management solutions like messaging-oriented middleware, an Enterprise Service Bus (ESB), Enterprise Application Integration patterns (EAI), or API Gateways. The service mesh may have minor feature overlap with some of those, but as a whole it’s oriented around a larger problem set.
The service mesh is different because it’s implemented as infrastructure that lives outside of your applications. Its value is primarily realized when examining management of RPCs (or messages), but its value extends to management of all inbound and outbound traffic. Rather than coding that remote communication management directly into your apps, they can instead utilize a series of interconnected proxies (or a “mesh”) where that logic can be decoupled from your apps and unburden that responsibility from developers.
Okay, What Should I Choose?
Before looking at specific products in the service mesh category, it helps your navigation if you start with clear answers to the following operational and technological questions.
- Am I and my organization ready for a service mesh? Using any new tool comes at the cost of learning to implement, use, and maintain it. Be sure your selection is worth the cognitive investment based on your readiness for the solution. You’ll know you’re ready for a service mesh if you manage a distributed application that makes a lot of different service calls (i.e. microservices).
- What problems am I having today? When managing your distributed production apps, where are the biggest pain points? Is it things like observability, understanding service dependencies, managing security, or managing fragility? If the answer to any of those is yes, then you’re super ready for a service mesh. Remember which pain points hurt most, because you’re going to need that in a moment.
- What platforms do you need to support? Where does your distributed application run? Aside from just supporting your container management platform of choice, will you need to connect the services you’re concerned about managing with a service mesh to other services that may not live in the service mesh? How far can you extend the reach of the particular service mesh product you’re considering?
- What level of observability do your services have today? The most easily realized benefit of the service mesh is transparent out-of-the-box visibility deep into service communication. How important is it for your organization and where are the gaps today? This is a frequently overlooked concern, but it’s the first one you’ll probably get value from. (Remember your pain points!)
- What functionalities of a service mesh do you already have? How will that play out in your when you introduce a service mesh? Related to the above, how many solutions have you already built that mimic feature functionality in the service mesh you’re considering? Will that present a problem when you introduce it? How will you roll out that new functionality without disruption or deprecate existing functionality that can be replaced? Are the integrations you need supported?
- What does the division of responsibility look like in your teams? Are individual development teams expecting to manage their own proxy configurations? Is control maintained by a central platform operations team? Whatever your organizational responsibilities are, you should ensure that the service mesh you consider allows you to distribute control in a way that makes sense for your organization.
- Do you favor centralized or decentralized functionality? Depending on the size and complexity of your deployments, do you favor implementations like a pool of host-based proxies or should you go through the potential complexities of using sidecar deployment models? What organizational drivers influence that decision in your environment?
- What support expectations do you and your team have? Are typical open-source community support standards enough for your team? What sort of tolerance do you have for rapidly evolving product features and standards? Do you need a commercial support option? These considerations are important when running in production.
Of course, the answers are specific to your context. There’s no universally correct choice for everyone. But keep these things in mind while comparing feature sets, design philosophies, and target uses cases.
Product Comparisons
For this guide, we’re focusing on the four open-source products available today. We’ll cover them by order of release date. These summaries are meant to highlight important distinctions between different service mesh options.
Linkerd
Linkerd (pronounced “linker-dee”) was first released Febuary 2016 as an open-source project sponsored by Buoyant. It was the first product to popularize the “service mesh” term. Linkerd is designed as a powerful, multi-platform, feature-rich service mesh that can run anywhere. Built on Twitter’s Finagle library, Linkerd is written in Scala and runs on the JVM. It can scale up to manage tens of thousands of requests per second, per instance.
Notable features include:
- All of the “table stakes” features (listed above),
- Support for multiple platforms (Docker, Kubernetes, DC/OS, Amazon ECS, or any stand-alone machine),
- Built-in service discovery abstractions to unite multiple systems,
- Support for gRPC, HTTP/2, and HTTP/1.x requests + all TCP traffic.
Linkerd includes both a proxying data plane and the Namerd (“namer-dee”) control plane all in one package. Linkerd is an open-source project, but it is also commercially supported by Buoyant. As of April 2018, over 50 companies are running Linkerd in production and it has a proven track record, having managed over one trillion service requests among its users.
Envoy
Envoy was first released in Oct 2016 as an open-source project by Matt Klein and the team at Lyft. It is written as a high performance C++ application proxy designed for modern cloud-native services architectures. Envoy is designed to be used either as a standalone proxying layer or as a “universal data plane” for service mesh architectures. Envoy has a diverse community made up of contributors who use it in production.
Notable features include:
- All of the “table stakes” features (when paired with a control plane, like Istio),
- Low p99 tail latencies at scale when running under load,
- Acts as a L3/L4 filter at its core with many L7 filters provided out of the box,
- Support for gRPC, and HTTP/2 (upstream/downstream),
- API-driven, dynamic configuration, hot reloads,
- Strong focus on metric collection, tracing, and overall observability.
Specifically on serving as a foundation for more advanced application proxies, Envoy fills the “data plane” portion of a service mesh architecture. Envoy is a performant solution with a small resource footprint that makes it amenable to running it as either a shared-proxy or sidecar-proxy deployment model. Envoy is community supported or from commercial vendors like Turbine Labs. You can also find Envoy embedded in security frameworks, gateways, or other service mesh solutions like Istio (see next section). When paired with the Istio control plane, Envoy can provides all “table stakes” service mesh features.
Istio
Istio was first released in May 2017 as an open-source collaboration between Lyft, IBM, Google (with other partners, like Red Hat, and many others joining soon after). Istio is designed to provide a universal control plane to manage a variety of underlying service proxies (it pairs with Envoy by default). Istio initially targeted Kubernetes deployments, but was written from the ground up to be platform agnostic. The Istio control plane is meant to be extensible and is written in Go. The Istio project focuses on the design principles of performance and scale, portability, and maintaining loosely coupled components for flexibility.
Notable features include:
- All of the table stakes features (when paired with a data plane, like Envoy),
- Security features including identity, key management, and RBAC,
- Fault injection,
- Support for gRPC, HTTP/2, HTTP/1.x, WebSockets, and all TCP traffic,
- Sophisticated policy, quota, and rate limiting,
- Multi-platform, hybrid deployment.
The Istio control plane focuses on providing operators many different constructs for composing management policy. Its design goals mean that components are written for a number of different applications, which is part of what makes it possible to pair Istio with a different underlying data plane, like the commercially-licensed Nginx proxy. Istio must be paired with an underlying proxy.
Conduit
Conduit was first released in Dec 2017 as another open-source project sponsored by Buoyant. Rather than optimizing for a variety of platforms, Conduit aims to drastically simplify the service mesh user experience for Kubernetes. Conduit is focused on being lightweight, performant, secure, and incredibly easy to both understand and use. Conduit contains both a data plane (written in Rust) and a control plane (written in Go).
Notable features include:
- All of the table stakes features (some are pending roadmap items as of Apr 2018),
- Extremely fast and predictable performance (sub-1ms p99 latency),
- A native Kubernetes user experience (only supports Kubernetes),
- Support for gRPC, HTTP/2, and HTTP/1.x requests + all TCP traffic.
Conduit centers around a minimalist architecture and zero config philosophy, designed to work with very little user interaction out-of-the-box. Built from lessons learned supporting production service mesh users, Conduit is designed for users seeking to solve the challenges of managing distributed apps in production with minimal additional complexity.
Conclusion
This introduction to product design and differentiating features is meant to help you determine where your service mesh journey should start. Evaluating options requires due diligence and we encourage you to demo the different solutions for yourself to see what actually works best in your environment.
This guide is the result of work between Christian Posta and myself. Posta works for Red Hat, one of the main contributors to the Istio service mesh. I work for Buoyant, the company sponsoring both the Linkerd and Conduit service meshes. By definition, that makes us competitors. Both Posta and I have long careers working with open-source as users, contributors, and vendors. We decided to put aside any differences as competitors in order to better use the insights we have into the ecosystem for the benefit of end users. We hope this guide helps you more effectively start down the path of evaluating what’s right for you.
For more depth, we also presented a joint webinar that further explores these product comparisons. If you have more specific questions (Linkerd, Envoy, Istio, and #conduit on Linkerd Slack). You can also reach either Posta or myself directly via Twitter, the CNCF Slack group, or the Kubernetes Slack group. We’d love to hear about your journey into navigating the service mesh ecosystem and how we can help get you started.
Christian Posta contributed to this article.