Add It Up: How Long Does a Machine Learning Deployment Take?

Creating and deploying machine learning (ML) models supposedly takes too much time. Quantifying this problem is difficult, not least because there are so many job roles involved with a machine learning pipeline. With that caveat, let us introduce Algorithmia’s “2020 State of Enterprise ML.” Conducted in October 2019, 63% of the 745 respondents have already developed and deployed a machine learning model into production. On average, 40% of companies said it takes more than a month to deploy an ML model into production, 28% do so in eight to 30 days, while only 14% could do so in seven days or less.
We believe Algorithmia’s estimate is much closer to reality than that reported in a Dotscience survey from earlier in the year that reported 80% of respondents’ companies take more than six months to deploy an artificial intelligence (AI) or ML model into production. That data point is misleading because it includes respondents that are still evaluating use cases and are in the process of deploying their first ML model. Of course, this in and of itself a substantial concern. In fact, 78% of AI or ML projects involving training an AI model stall at some point before deployment according to another 2019 survey, this one of 277 data scientists and AI professionals by data labeling company Alegion.

Source: Algorithmia’s “2020 State of Enterprise ML”. This question about how long it takes to deploy an ML model into production was only asked to a subset of respondents at a company that has an ML model production.
The study also measures the effort data scientists and developers expend deploying ML models. At companies that have already deployed a model, 52% of business leaders and ML practitioners (e.g., data scientists, developers) believe their data scientists spend more than a quarter of their day doing so. When it comes to developers’ time, there is less certainty, with 54% of business leaders saying it takes a quarter of their developers’ time, while 41% of ML practitioners think developers exert that much effort.

Source: Algorithmia’s “2020 State of Enterprise ML.”
The Algorithmia survey did not specify exactly what is included in the “deployment process,” and the industry does not appear to have agreed on specific terminology for the various parts of the machine learning pipeline. Algorithmia claims to have an “AI layer” that takes care of the process of prepping, testing and managing trained models. In this context, model selection as well as of models, training tools such as Data Robot and MLflow, and the infrastructure (i.e., compute, data storage/ingestion) required to run models. Despite semantic challenges, a 2018 Kaggle survey is comparable. It found that 41% of data science projects are dedicated to gathering and cleaning data, 20% of time goes to building and selecting a model, and only 9% to actually putting a model into production and running it.
Scaling up and “versioning and reproducibility” of models will be the top machine learning challenges in 2020, according to the Algorithmia study. It appears that other issues, such as costs and a model’s predictive power, will take a back seat to time-to-market for companies that have incorporated ML into existing products and operations. To address versioning challenges, ThoughtWorks’ latest Technology Radar is recommending that enterprises look a software engineering approach they define as Continuous Delivery for Machine Learning (CD4ML). A detailed article from the Martin Fowler site about CD4ML explains how “cross-functional teams can produce machine learning applications based on code, data, and models in small and safe increments that can be reproduced and reliably released at any time, in short adaptation cycles.” Using this approach, the authors suggest that future studies can track the speed and level of automation of a “data pipeline” and “model training pipeline” as separate from the traditional “continuous delivery pipelines.”
Odds and Ends
The New Stack has a lot of articles detailing how developers and DevOps teams are dealing with machine learning. Here is a sampling:
- How Artificial Intelligence and Machine Learning Are Disrupting DevOps
- How AutoML Puts the Power of AI in the Hands of Business Analysts
- AWS Launches an IDE to Manage the Full Machine Learning Lifecycle
The following graphics support the article’s analysis:

Source: Alegion and Dimensional Research’s “What data scientists tell us about AI model training today.” A third of AI/ML projects stall at the proof of concept phase, while only about a fifth AI model training projects are not delayed.
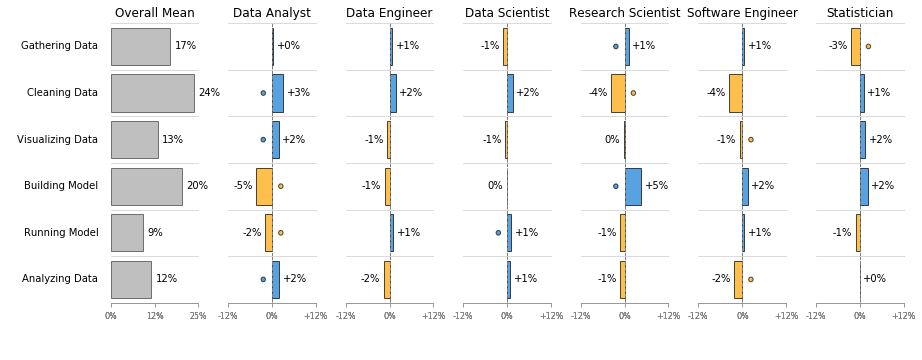
Source: Vilmos Müller’s analysis of of the 2018 Kaggle ML & DS Survey. The chart represents answers to this question: “During a data science project, approximately what proportion of your time is devoted to the following activities?”
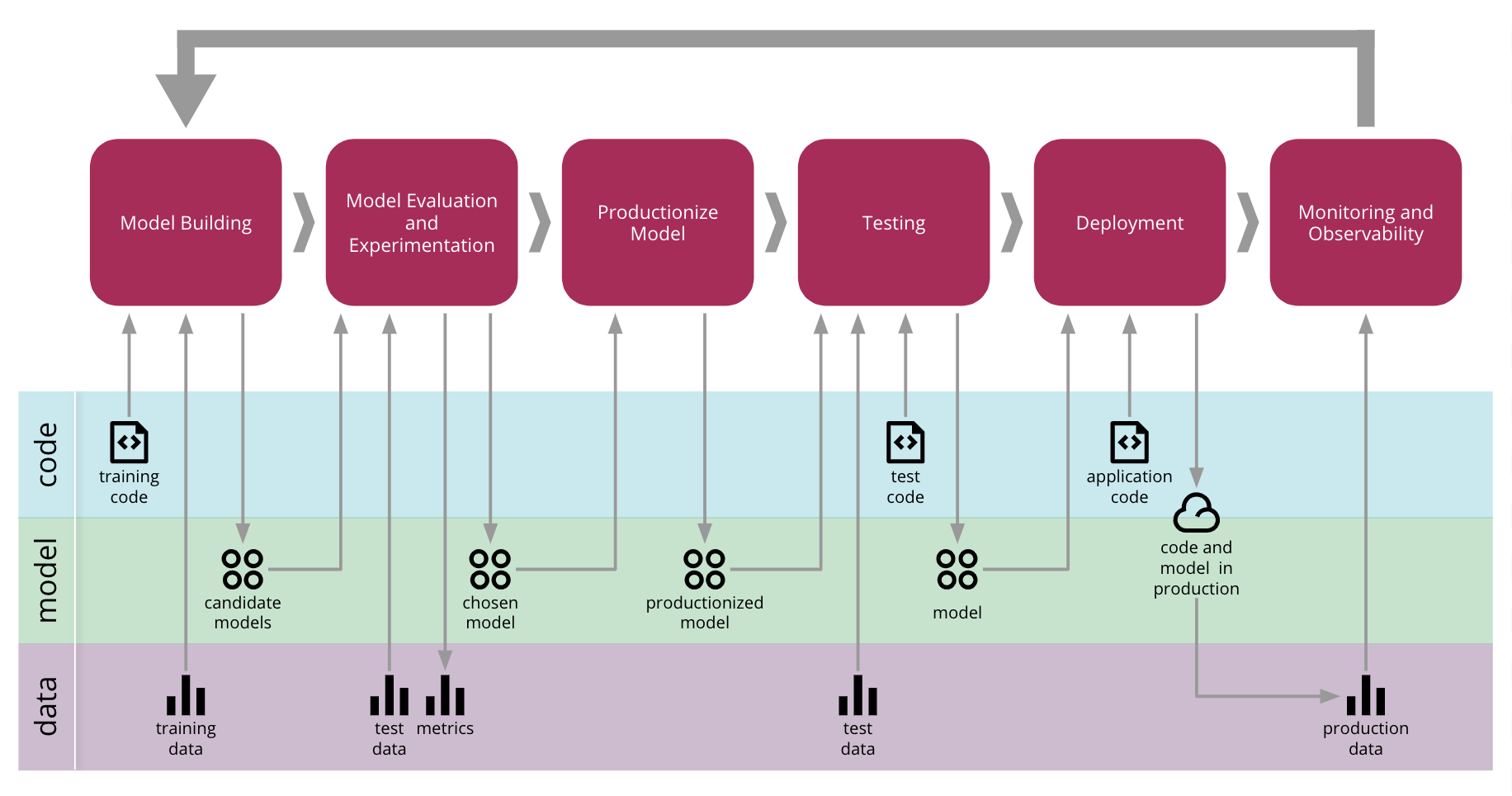
“Continuous Delivery for Machine Learning End-to-end Process.” Source: Martin Fowler
