Anaconda’s Python/R Distribution Sets the Stage for Scalable Machine Learning

When it comes to managing the development of machine learning models, git just doesn’t get it.
This is the lesson learned by Max Humber, a data scientist with the Canadian finance company Wealthsimple, an insight that he shared in a talk at this year’s Anaconda annual user conference, AnacondaCon, held in Austin, Texas.
“Git manages for code, it is not really great for managing model parameters,” he said. Finding the best model, and tuning it accordingly involves a lot trial-and-error. Much of it involves swapping models in and out of the code, then adjusting the parameters. Saving each version of the program for every single test is cumbersome, plus there is no mechanism for collecting information about the performance of that configuration.
So Humber created Mummify, which logs performance information for each run of a model. It saves all the material it creates in git, but doesn’t require the end-user to understand the version control software, which can be a demanding task for developers, Humber said.
Currently, Humber noted, AI models, when they are moved to production, become black boxes, brittle and difficult for the IT staff to work with. There are many aspects of developing machine learning models that really are aspects of maintaining infrastructure, including data cleansing and preparation, logging, instrumentation, workflow pipelines, and other aspects.
And many of these aspects are completely new to a company’s IT staff.
“I think IT departments are going to have to get better at handling some diversity of architecture,” said Peter Wang, a co-founder and chief technology officer of Anaconda. The days of everyone using the same stack in the company are coming to an end. “Right now, every tier of every stack is changing so fast. Monoculture is dead.”
Data Science in the Enterprise
In 2014, Gartner had predicted that 60 percent of all big data projects would fail by 2017. The actual percentage turned out to be closer to 85 percent, noted Hussain Sultan, a partner of at Full Spectrum Analytics, a consulting firm that has done some work on financial tech AI systems.

Hussain Sultan (right) and Tim Horan.
A big culprit for this high rate of failure was the inability to offer clear business outcomes for these projects, or even to integrate these projects into the larger operational IT infrastructure. In many cases, an organization will develop a proof-of-concept, but never bring the end product to market.
“The new insights, models, and strategies don’t fit into the older implementation process,” added Tim Horan, also from Full Spectrum Analytics. Data scientists may use new tools, or look for techniques that can’t be supported through legacy infrastructure. He pointed to SAS in particular as a widely-used analytics package that nevertheless doesn’t support the non-linear models needed for machine learning work.
This idea of the data scientist being pitted, unnecessarily, against the IT department was a theme that Anaconda had emphasized through the conference. For the opening kickoff, the company showed off a mock trailer for a fictional movie called “Pyception,” (an amalgamation of the word “Python” and the name of the blockbuster film from a few years back called “Inception”). It’s all about a team of data scientists that try to get out of “the sandbox” and into an actual “production environment,” and they must confront the IT Department, which is portrayed in the trailer as remorseless killers:
“Why are they shooting at us?”
“They’re the IT team. They won’t let our Python models out of the sandbox. They want us to rewrite everything in Java…”
The point of this faux clip, and this week’s conference, of course, is that IT pros and data scientists don’t have to be at odds at one another, that the data scientists could create a machine learning model and not worry about the supporting infrastructure, and have that model run anywhere, exactly the same. In short, Anaconda wants to free data scientists “from the sandbox,” Wang quipped.
Model Management, Package Management
Through multiple sessions, Anaconda had stressed how easily that its Anaconda Enterprise Platform can be used for machine learning and be folded into existing IT operations. The software was designed to provide a full range of support for the Python programming language, and later the R statistical language. For its most recent release late last year, version 5, the package was re-architected to fit into DevOps-styled continuous integration and deployment operations.
The software is now built around Docker and Kubernetes, and integrates with the Lightweight Directory Access Protocol (LDAP) and Microsoft’s Active Directory for authentication and authorization. As a result, it can be used to package various work products of its users so that they can be easily reused by others on the network, as well as provide a way to run these jobs across distributed systems in a scalable manner, noted Michael Grant, Anaconda director of technical consulting.
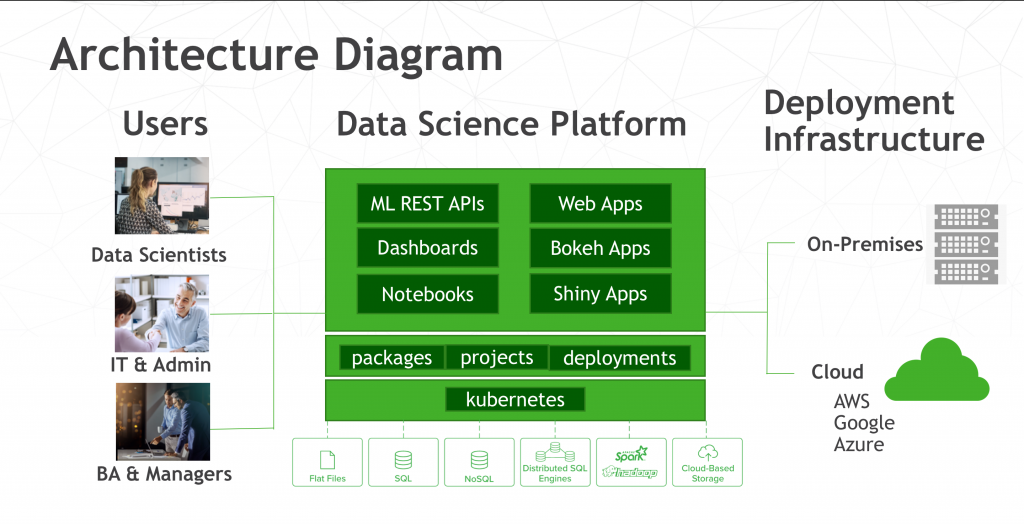
In the realm of machine learning, these capabilities can be used to package models, Grant noted. Containerizing models provides certain benefits: They can be tested or validated by other sources, without worrying about dependencies, and with the assurance, the running the models on different systems will still provide the same results. The data scientists themselves don’t have to worry about package management, given that for each build, Anaconda itself pulls the latest dependencies for each build.
In particular, working with Anaconda’s packaging tool Conda can help smooth over issues with versioning. In his presentation, Grant showed how all the components of a model, such as the framework, the validation data, libraries (Panda, Numpy) all have a different release schedule and move forward on their own cadences. Conda ensures the correct dependency packages are installed, with each instance of a model packaged with distinct copies of Python and/or R.
Conda can also be used for packaging and versioning testing data, in addition to the code itself. A cronjob or Github trigger can be used to initiate a new build of a model, which then can be automatically shipped to different channels for different builds, such as ones for development, production and experimental. Different channels can be yoked to different automated testing routines, in effect providing the basis for automating a workflow channel that may involve multiple approvals and testing.
These tools “help you establish a precise computational environment in which your models will run,” Grant said.
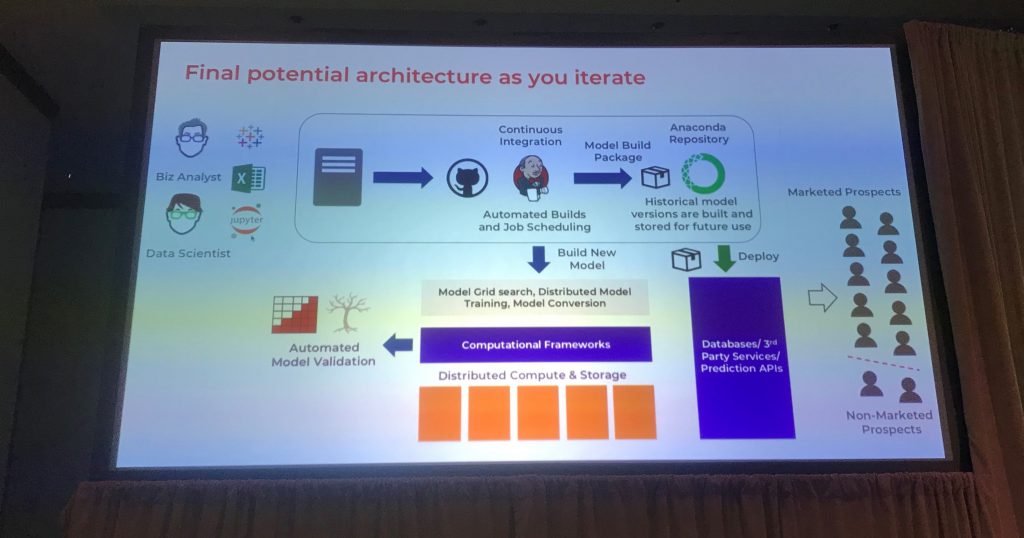
Hussain Sultan (right) and Tim Horan’s full lifecycle model for machine learning development.
In another session, Duane Lawrence, Anaconda vice president of technical services, offered a rundown of how Conda helps package management at the enterprise level as well. To handle dependency management, Conda can download the latest version, or a version of your choice down to the build number, from Anaconda itself.
If the IT staff is hesitant to open up a firewall to provide a permanent connection to Anaconda, they can also do online package mirroring, where the packages are kept on-prem and are periodically updated at specified times, Lawrence said. Only those packages that are needed can be periodically downloaded. The organization could also set up a DMZ, where the packages are downloaded to an intermediate server, where they can go through testing and then distributed across the network once validated.
Conda has the ability to create virtual distributions, each of which may contain specific versions of libraries, allowing admins to run multiple packages on the same set of servers. The common packages across distributions can be hard-linked, so multiple copies don’t gobble up disk space.
“Every analysis can run in its own environment,” Lawrence said. “You can have as many environments as you need to run in production.”