Machine Learning Made Easy


Remember the movie “The Imitation Game”? The tragic story of a brilliant man who decrypted secret German Enigma messages, indirectly shortened World War II, saved millions of lives, and was later charged for homosexuality, forced to undergo chemical treatment, and ended his life shortly after?
The real Alan Turing accomplished many more brilliant miracles than this. He also published papers on theories of artificial intelligence (AI). In fact, the title “The Imitation Game” had little to do with the movie. It was a game he mentioned in one of his papers where humans will one day engineer a machine to imitate humans so well that a human on the other side of the room will be fooled he was communicating with another human. Turing was a pioneer in the field of computer science. Only after his death would he be known as the father of AI.
In the movie, he creates a machine that attempts to exhaust all possibilities of combinations of letters and words, trying to match the secret enigma code into meaningful words. The machine is on all day and all night non-stop. Imagine how long it’ll take a human to look at all the possible patterns and try to decipher encrypted secret war messages. The machine couldn’t have deciphered the code without Turing giving it instructions of what to do and how to do it and Turing wouldn’t have been able to crack the code on his own either. It was the beautiful marriage of both a human brain and a machine’s speed and accuracy.
Relationship Between AI, Machine Learning, and Deep Learning
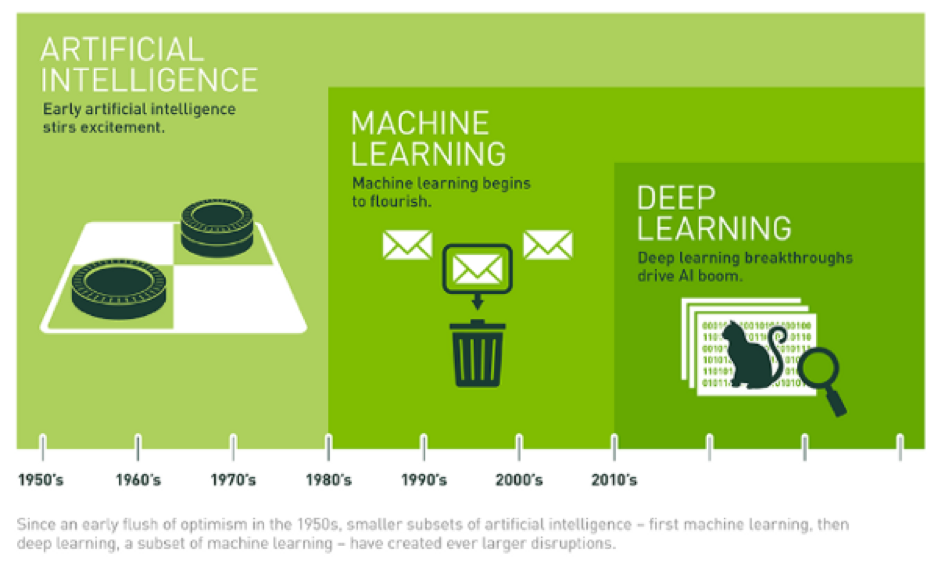
ML is a subfield of AI. DL is a subfield of ML (Source: Nvidia)
Artificial intelligence (AI) is the field that seeks to study and design machines that are capable of human intelligence and decision making. Machine Learning (ML) is a subfield of AI that uses statistical mathematical approaches in an attempt to achieve AI.
Stanford University defines ML as “the science of getting computers to act without being explicitly programmed.” Deep Learning (DL) is a subfield of ML that implements machine learning similar to the biology of our brains, taking in data of many dimensions and processing them through several networks and neural network layers.
That’s tough to digest! Don’t worry, I’ll explain. To understand ML, let’s understand it from a bigger scope of things, starting with AI.
Why Do We Have This Field and Why Does It Matter?
In the 1950’s, modern day calculators and ATM bank machines would be considered AI since the act of calculating, withdrawing, and depositing money can be considered human intelligence. Fast forward to today, these tools are just “AI effects” because the definition of AI has evolved from just human intelligence to also demonstrating decision making
Imagine you wanted to go to the nearest coffee shop that’s open right now at 5 a.m. Instead of looking at a collection of menus for the hours of operation and seeing which shop is closest, now we can ask voice assistants Alexa, Google Assistant, Siri, or Cortana,“What’s the nearest coffee shop?”
Now imagine you watched a comedy and couldn’t get enough of laughing. Instead of manually searching through movie titles, trying to figure out if the type of movie is a comedy, and then collecting a list of potential comedies to watch next, we can now rely on Netflix or YouTube to display a list of recommendations immediately after the movie finishes playing. Isn’t it amazingly convenient that the next YouTube video that automatically plays is always a similar topic to the video you previously watched, given there are so many videos of different topics out there?
These are all examples of modern-day AI in progress. While an ATM machine can complete one task of giving me $100 when I press the withdraw button, self-driving cars can complete multiple spontaneous tasks that it decides is right: drive straight at a green light, slow down, turn, stop at the destination. To generalize, AI’s carry out a list of tasks. The more tasks it can carry out, the more intelligent it seems.
“AI is the new electricity” — Andrew Ng
With this ambitious goal to empower humans, AI is broken into smaller more specialized subfields. Machine Learning is the most essential subfield. An approach to achieving AI, we teach machines all our human knowledge and train them to take appropriate courses of action. Learning about the world and figuring out how to act is the foundation of human behavior and consequently, machine learning is the building block of AI.
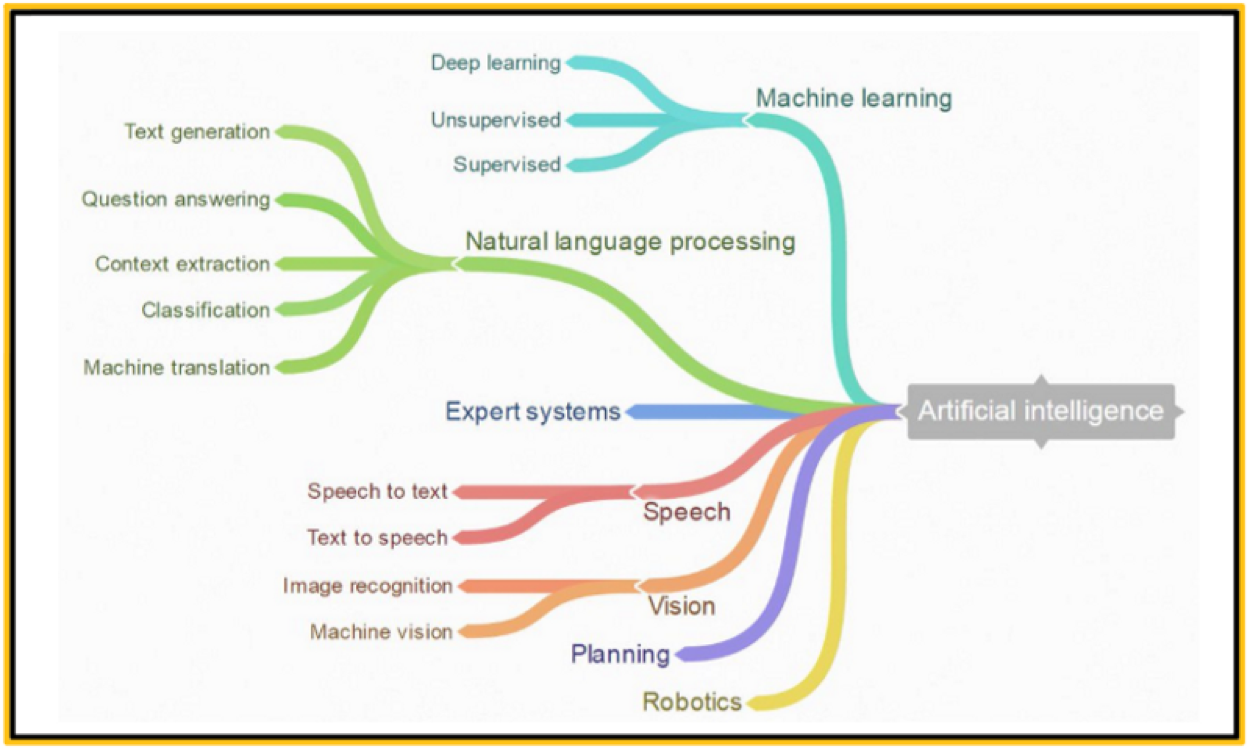
Approaches to AI. Machine Learning is the building block. (Image from Francesco Marconi)
An Approach to Achieve AI by Teaching Machines to Learn
On a quest for artificial intelligence, Arthur Samuel at IBM coined the term “Machine Learning” in 1959. Machine Learning involves a lot of math as you’ll see in a little bit but it’s only a narrow section of data science. This field is also very similar to Statistics and that’s because it’s Applied Statistics.
Believe it or not, “intelligent” human decisions and actions can be boiled down to just mere patterns and can be recreated utilizing math. Remember how you first learned how to cross the street? You waited till the lights turned and the cars on the left and right of you stopped at their appropriate lines. If a car suddenly started moving, you reassessed if it was safe to cross the road. Do you recognize the patterns? If the light is red, stop. Else if the light is not red, walk. How our decisions involve math are a little more subtle. If we detect a car moving towards us when we’re walking, we predict the possibility that we need to stop walking or move away. The closer the car’s angle is towards us and the faster the speed it’s going, the higher the percentage we need to run.
While humans learn from experiences, machines learn from “data” (when we tag ourselves in our Facebook photos, our text messages, and any sets of data we supply it.) The more experiences humans have and the more data the machine has, the more accurate we are/it is. Three ways we teach machines are Supervised, Unsupervised, and Reinforcement Learning. There is a long list of algorithms to accomplish each type of learning. We’ll only look at some. “Algorithms” in machine learning context are sets of step by step mathematical instructions we give the machine to run. After a machine runs through this algorithm, it becomes a “model” (a hypothesis of how it thinks the world works.) These models undergo constant improvement so the machine perfects the skill. Let’s look at examples.
Is This a Cat?
One way humans learn is through “training.” We can classify a cat because we’ve been told what a cat is and we’ve seen more than enough cats to count. We can classify if an email is spam because we know what spam mail is like. We can infer we were just served wine because of the color of the liquid and the alcohol content. We can predict the cost of a house by looking at its location, size, and amenities. We can predict if a cancer is malignant by looking at patterns of previous cancers. To train a machine to learn this way, we give it a set of “training data” with “desired output.”
To “train” the machine to classify objects like cats, we find millions of cat photos on the internet. The more data we give the machine, the more accurate. So we include pictures of cats of different colors, different sizes, at different angles, yawning, jumping, stretching, and anything else we can think of. We give the machine the “desired output” for this training dataset by labeling the photos with “cat.” After the machine has gone through a popular algorithm called the “Classification algorithm,” it has learned a “model” of how the world of cats work.
Now to test the model and see if it learned, we give it a photo and ask if it’s a cat. The machine begins to run the model. Looking at each “feature” in the photo, it’ll give it a “weight.” After some more calculations we instructed it to do, it’ll have computed percentages (e.g. 50 percent chair, 70 percent fluffy rug, 30 percent cat). At the end, it’ll return the class with the highest numerical value — fluffy rug. If the model told us it’s a cat, we have to train it with even more photos. Maybe more photos of white cats. This is an example of how machines can identify/classify objects.
To train the machine to predict the possibility of a “yes” or “no,” we might give it training data of previous spam emails. Let’s say 40 percent of the emails in this training data with the phrase “Last Chance” was labeled spam and 85 percent of them with the phrase “Act Now” was labeled spam. After the machine is given this training data, it has a model of how it thinks spam emails work.
Now we test our model with a new email. Within our model, we might instruct it to say yes to any percentage higher than 80 and no to anything lower. When it receives a new email, searches and detects the phrase “Act Now,” it will label this email with 85 percent chance of being spam. Since this percentage is over the 80 percent that we set, it will return yes. This is the “Naive Bayes algorithm.”
To teach the machine how to predict and return numbers such as house prices, we might give it training data of existing house prices. It runs through a “Linear Regression algorithm” and arrives at a model that looks like the chart below. Its model hypothesizes a linear correlation between the size of the house in square feet and the price. With this model, it’ll confidently predict a number based on where it plots the house.
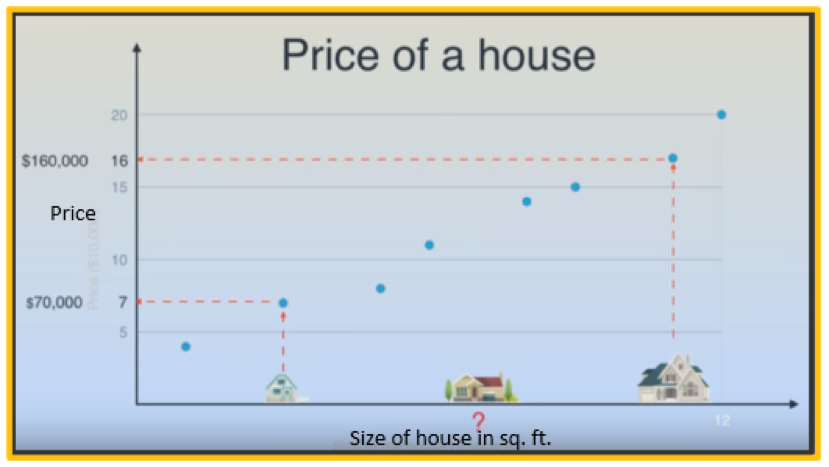
Using a linear correlation to teach the machine how to predict house prices (Video source: Luis Serrano)
Unsupervised Learning
Another way humans learn is by discovering patterns. We learn our credit card is stolen when we discover abnormal high spending. We learn that drinking a cold beer or a cold sangria is more satisfying than drinking room temperature red wine on a hot summer day. We learn that if we’ve watched a few horror movies and still don’t like it, we probably don’t want to watch any more horror movies. This instance of learning is when we have a lot of experiences and data but instead of having an answer key to match or compare new experiences against, we ask the machine to crunch some numbers to look for and discover patterns that lead to brand new conclusions that we might not have thought of.
To see if there’s anything interesting in bank transactions, we might feed a machine customer transaction data. It’ll look at the features and compare their consistency for any patterns. If there’s a purchase that’s a significant outlier (spending is abnormally high or abnormally low compared to the rest of the data), the machine just discovered potential credit card fraud. Now you see how Chase Bank probably figured out how to email you to confirm a suspicious transaction.
Association Discovery
When we feed a machine data on our sleep patterns, it might learn to associate variables. It might associate human sleep hours to usually be around 11 p.m. to 5 a.m. Of course, the more data we give it, the more accurate (for those who argue they never sleep!) For now the machine has learned that a great time to plot human destruction is between the hours 11 p.m. to 5 a.m. Just kidding.
To find meaningful data in the entertainment world, we might feed a machine data on customer habits. It might notice that there’s a high frequency of customers buying baby diapers and baby cribs. The machine might not know what diapers or cribs are but based on the calculations of how many times they were brought together versus how many times diapers and bananas were bought together, it knows there’s something going on. It now starts to group similar products together. This is the same for movies and video watching. Now you get a glimpse of how Amazon, Youtube, and Netflix’s “recommendation system” works.

Machines cluster similar products together based on data. Because you watched one movie, it’ll recommend you all the other movies it grouped in this category. (Image from Netflix)
Reinforcement Learning
The last way we learn is by discovering steps and strategies and training ourselves over and over so that we can have a higher chance of getting what we want.
Games are a classic example. Think of a game where you’ve played over and over until you’ve learned the sequence of steps you need to take to win. Now, imagine playing out all the possibilities and being able to store all the steps that led you to win in your head. Next time you play, you know exactly what moves you should make no matter what move your opponent makes. Or do you? It’s hard for humans to store and recall all this memory but machines can.
Understanding this, it’s no surprise machines have successfully beat humans in games. IBM’s Deep Blue machine beat world class chess champion Garry Kasparov in chess in 1997 and Google’s AlphaGo beat world class champion Lee Sedol in Go in 2016 (supposedly said to be the hardest game.)
Tic-tac-toe is a fairly simple game where each player is either “X” or “O” and takes turns placing a piece on an empty square on a board until three consecutive pieces are found. Machine learning experts call the player “agent,” the end goal of winning with three consecutive pieces the “reward,” the Tic-tac-toe game as the “environment,” the current game state as the “state,” and the move taken as the “action.” The important thing to note is how the machine learns what to do in a complex uncertain environment with no idea how its actions will affect it attaining its reward. Like humans, it can only sense its environment by reassessing how every action got it closer or farther from its reward.
Every time humans play, we pick up strategies (e.g. starting first has an advantage, or putting your piece in the center limits your opponent’s chances of winning.) When the machines pick up these strategies, they are more mathematically accurate.
Utilizing math (that I’ll make up), they might remember that starting first has a 75 percent chance of winning because out of the 2,000 times it played, it won 1,000 times and out of the 1000 times, 750 times it had the first move. Every step it makes, we tell it to crunch numbers and associate them with different variables. To decide which box to put its game piece next, we’ve instructed it to crunch some more numbers to figure out which box will increase the number associated with the reward. Every time after the machine makes a move, it reassesses its state and recalculates its reward. If its action led it closer to winning, the number associated with its reward increases, and vice versa.
We instruct the machines to basically repeat these mathematical steps over and over again; storing data of its moves, recalculating its chances of winning with every move, updating the number associated with its reward, and deciding on the next best possible move by figuring out what move would minimize loss of the reward. We might instruct the machine to keep playing against different versions of itself over and over and maybe only stop when it wins 100 percent of the last 100 games it played. This is the “Minimax algorithm.”
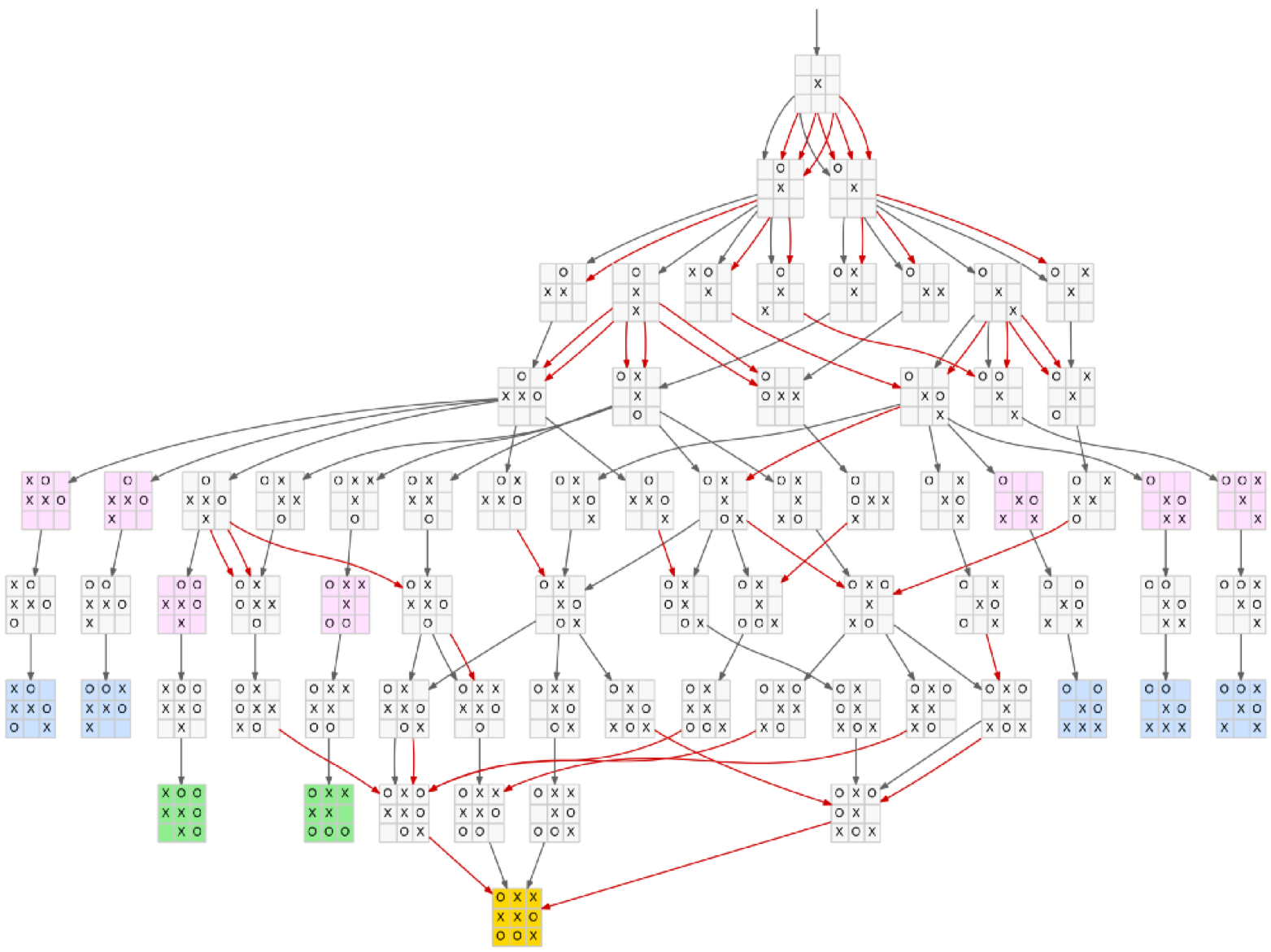
Machines can store all possibilities of a game like TicTacToe in its memory ( Image Courtesy of Occasional Enthusiast)
Deep Learning rose out as a subfield to Machine Learning. While Machine Learning is a way to achieve AI, Deep Learning is a way to implement Machine Learning given data of many dimensions. Similar to the biology of our human brains, we put data, “input”, through multiple “neural networks,” in “neural layers,” and get “output.” Each function (task) is a “neuron” and each neuron is a “layer.” The more networks, the more complex. Hence the name “Deep” Learning. Facial recognition (recognizing whose face is seen), computer vision (classifying and recognizing what’s happening in an image), and speech recognition (translating your spoken speech to machine understandable text) use deep learning. Let’s look at examples.
A Neural Network
Text Recognition
Deep learning is a subset of many neural networks. But what is a single neural network? How do you think a computer might recognize a “9” written with a sloppy handwriting? Let’s look at possible layers the machine might go through until it reaches the conclusion that the digit “9” is written.
The “9” is represented within a 28 by 28-pixel canvas. One layer (neuron) might be to recognize the parts of the text that form a round circle or the parts that form lines. There might be special “weights” (a special numerical value) given to special features meaning we value that feature the most (e.g. the round circle). This neuron now holds a number and affects the next neuron. The second layer might be to put together that one circle is found and one straight line is found.
We might add a “bias” factor because it might be easy to find straight lines and that’s biased, so some more math is crunched. The last layer might go through all the numerical digits to see which is composed of one circle and one line. Imagine repeating these steps for a sentence, in the forms of numbers, alphabets, and special characters (“?”, “.”, “{}”, etc.)
As with everything in machine learning, the models need to be tested and refined. If the “9” was not recognized, we would tune the parameters we give it such as the weight and the bias factors. In order to accurately and delicately not completely flip the output, experts will use a “sigmoid function” that uses math derivatives to tune the parameters. We always perfect the models.
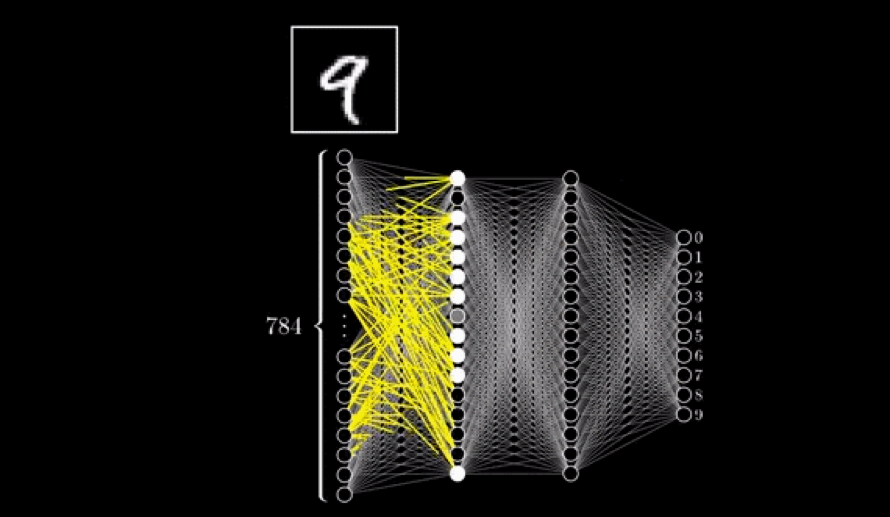
This is one neural network. Given text, the machine goes through hidden layers and detect “9” (Video Source)
This approach can be used for a number of tasks. One would be face recognition. To detect if a human face exists or not, it takes many machine learning algorithms to put together and recognize a face. So one neural layer in this deep learning process might be classifying and identifying specific features (teeth, pupil, nostrils.) Another layer might determine generalizations (if it’s a mouth, an eye, a nose.) Another layer might determine if this is, in fact, a human face or not.
Voice recognition is another task. Between the time you speak and the time a voice assistant like Alexa responds back to you, think about the many dimensions of data you are passing it. Multiple neural networks are assessing the input it’s receiving: which words you are saying, the language you’re speaking, if you’re asking a question.
How to Perfect Each ML, DL Model
Now that you’ve seen the three types of machine learning (supervised, unsupervised, and reinforced) and deep learning, there are three steps to learning. Based on what we know from our experiences/data, we can “predict/infer” something. Every time we predict/infer wrong, we learn from our “error/loss.” After each experience, we “refine/retrain” ourselves. This is the same way we perfect our machines after they train on these algorithms (set of step by step mathematical instructions) and create a model (hypothesis about how the world works.) After the models predict/infer, their answers go into another set of instructions that checks if it made an error. Whenever it does, we refine and tune our “hyperparameters” (the kinds of data like cat photos that we supply it) until we are satisfied with the model’s performance.
How to Know Which Model to Choose for Each Task
There are many algorithms that can answer the same question or accomplish the same task. How do we know which to choose? We can predict how much a house will cost using unsupervised learning’s association discovery algorithm or supervised learning’s linear regression algorithm. In order to find the best algorithm, we put these models to the test by collecting the results they give and then seeing how “precise” they are each time and how “often they fail.” May the best algorithm win.
That was a lot! But hopefully, you’ve seen the tip of the iceberg of what machine learning is and how the combination of machine learning approaches into neural networks and deep learning can empower Artificial Intelligence with human intelligence and decision making. After training and refining the models, we essentially get “predictive models” that can help answer questions to things we should know from our data (e.g. Is this cancer malignant?) or help us predict unknowns (e.g. What trends are there in human behavior?) To contribute to machine learning and/or deep learning, we’d just need to sharpen our math skills, learn some programming languages, learn some frameworks, and be on our way to contributing to AI.