Platform-as-a-Service: The Key to Running a Continuous Deployment Pipeline

A six-year veteran of continuously deploying swarms of microservices to various Platform-as-a-Service environments, Ben Dodd kicked off a recent London Continuous Delivery Meetup by asking: What is the relationship you want to have with your Platform-as-a-Service (PaaS)?
Using the following metaphor of “Pizza-as-a-Service,” he says you’re only supposed to concentrate on what you want to accomplish, only focusing on the immediate task at hand: “Only care about our pizza, everything else is someone else’s concern.”
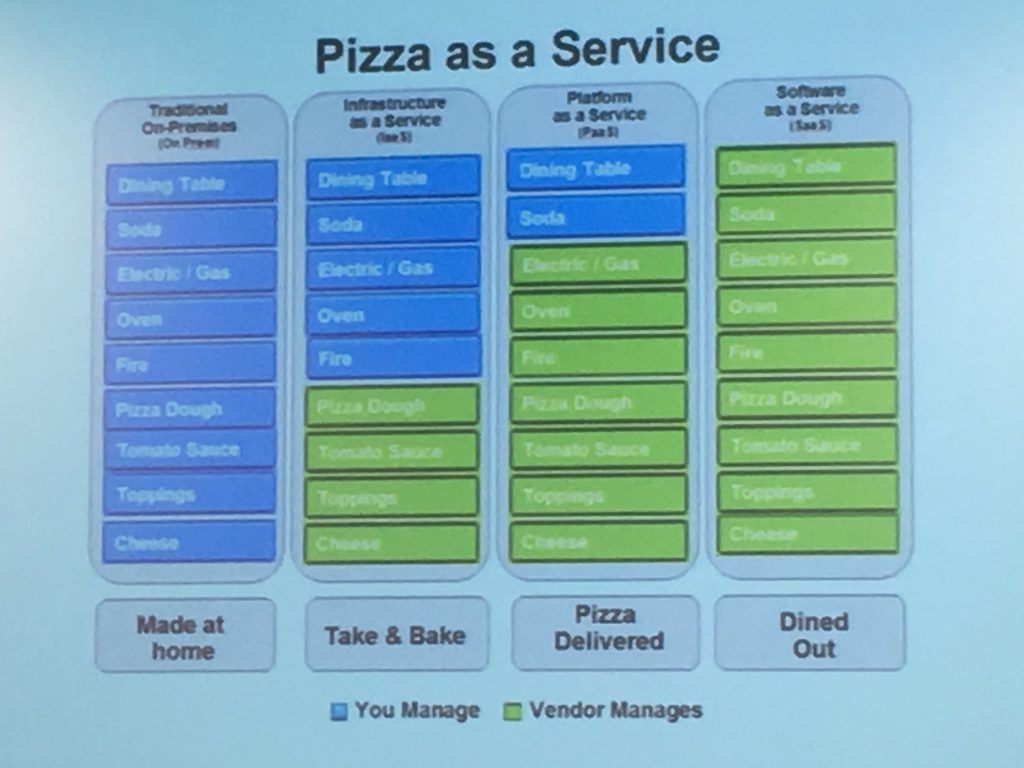
“As developers, we want to be spending time creating and pushing features, we do not want to have to worry about platforms and talking to operations. [It’s all about] getting feedback and getting those features in the hands of users,” he said.
“We want to deploy apps down a pipeline [and we] need PaaS to build a platform to deploy microservices,” he said. “The only way to effectively manage high-risk platforms is continuous deployment.”
Reasons Not to Build Your Own PaaS
Dodd offered a lot of excuses that teams make up to build their own PaaS that, in the end, really slow down business and that tie releases to the few “superheroes” on a team. All this collapses as soon as there are changes on your team or infrastructure. Building your own customized PaaS creates the following challenges:
Problem #1: Platform Work is Manual Work
Dodd says that you may have a few superheroes that can do everything but it takes time. In general, like the monkeys and the ladder experiment, people will commit to things by saying “It’s always worked like that.” But just because it always was, doesn’t mean it’s ever better.
Problem #2: “We are Super Special Snowflakes”
Similarly, a lot of teams tend to think that their organization is so special with different requirements than anybody else so they have to create a new PaaS. Then there will be a few superheroes who will set it up, but then when they leave, no one knows how to use your PaaS.
Problem #3: “We are a Risky Business”
Again, if you only build your own PaaS, you create more shared requests and a whole ticketing system just for the PaaS requests. Dodd says this only serves to create “more superheroes building more obstacles.” As you use the security excuse more to build your own PaaS, he says you’re really only building a slow and complicated Platform as a Silo.
Problem #4: We Need to Scale and Update”
“Updates every four weeks, two weeks to test each, so when do I get my new feature? It takes us two weeks to test because we’ve manually deployed, scaled, distributed — it ends up standing still, just updating,” Dodd said.
Problem #5: It Becomes Expensive
Dodd pointed out how especially in enterprises, once something is deployed, it’s not revisited for about six months, so people deploy and keep things up and running just in case because it took so long to get it up there. He argues in favor of deployment tools like Bosh that can get things going in a couple hours.
Dodd has witnessed how many organizations will either create their own PaaS or they’ll use an existing PaaS that they deploy manually, but can only test it when they go live.
With all of these paths, he said, “tests happen infrequently so there’s no real way to know that those platforms don’t have serious issues.”
PaaS Saving High-Risk, Once-a-Year Fundraiser
Dodd’s company Armakuni runs the donations platform behind the enormous annual Comic Relief fundraiser which during one big night each year sees up to 300 donations per second, raising £76 million this year alone.
“If we don’t collect then, people won’t come back,” Dodd said, pointing out how when people are moved by the program to donate, if the payment doesn’t go through, they won’t be as eager the next day.
To keep everything strong with only an annual feedback loop, it is run it all on a global, open-source, multi-cloud infrastructure, which makes the project incredibly high-risk. The layers of backup and planning in it has led to Gartner offering Comic Relief as an example of multi-cloud architecture.
They have servers and back-ups around the world, running on all major brands, so everything is the same even if one piece crashes.
“All parts are identical, whether AWS or Google or on-premise, is all identical — and any of these can do 300 per second,” Dodd said.
To achieve this, they had to make a trade-off.
“Comic Relief doesn’t need consistency in their data, they need availability,” he said. “Before, they could see the exact amount of money in there, but it’s hard to distribute. They needed to move away from a consistent data store to an architect solution to meet goals.”
He continued saying that it “Also had a pre-production continuously deploying environment, however that environment is then destroyed after a successful state because it was super expensive and the PaaS remembers what was the last good state.”
To accomplish this, they use the open-source deployment and lifecycle toolchain of Bosh, along with Cloud Foundry PaaS, and Concourse CI for highly declarative continuous integration.
He says outsourcing to an existing PaaS allows them to do a $cf push of their app: “Give me your app. I will run it for you, you do not need to know how that works.”
Dodd continued that “Bosh does a rolling deployment update from VM and tests that it updates successfully. That can be hundreds and hundreds of VMs with essentially zero downtime. And if it goes wrong, it’ll just roll back and stop.”
This multi-cloud architecture is also built on a mix of test-driven compliance, test-driven development and test-driven resilience.
“Requirements for resilience like backups have to be part of your pipeline, asserted every time someone makes a change, so they can work out who changed what and what happened,” Dodd said. “And then you need to track it all to see at what point your pipeline slows down.”
Building a Successful Pipeline with PaaS
Dodd concluded his talk by offering the following lessons learned about building a strong and stable pipeline:
- “You have to stick to it and not slow down your pipeline by taking shortcuts — just say no to your organization and stick to your guns. But you have to think about the risk to the organization and how you’re going to demonstrate it to the business side.”
- Use test-driven development using BATS.
- “We focused on the ‘what’ and ‘why’ not the ‘how.’ Do not engage with how it is currently done. The idea is to go to those sort of stakeholders and ask: What is your actual requirement like risk and compliance.” By answering these questions you can get into a fully automated process.
- The development team didn’t have production and staging named environments, allowing to shoot out at a moment’s notice.
- “We deployed in sociable times because we’re doing these updates on every single commit and doing it continuously — so we can stop having support teams come in at the middle of the night,” he said.
- Constantly optimize for short feedback loops
- Pair developers and operations up to learn together from each other from the start.
The Cloud Foundry Foundation is a sponsor of The New Stack.
